Syntax Reference¶
Below are syntax diagrams for Paxter language.
Document: Top-level document; parsing starts here. Once all fragments of the fragment list is parsed, the caret pointer must end exactly at the end of input text.

FragmentList: Consists of an interleaving of raw texts and @-commands, and ends with dynamically designated break pattern (which is simply tells where the fragment list stops).

For example, if preceding the fragment list is an opening brace pattern
##<#{, then the break (i.e. closing) pattern for this fragment list would be}#>##, which mirrors the opening pattern.Please note that by construction of the language, the non-empty raw text would never contain the break pattern; if it was the case then the parsing of fragment list would have terminated earlier. In other words, we non-greedily parses text within the fragment list.
The result of parsing fragment list is a
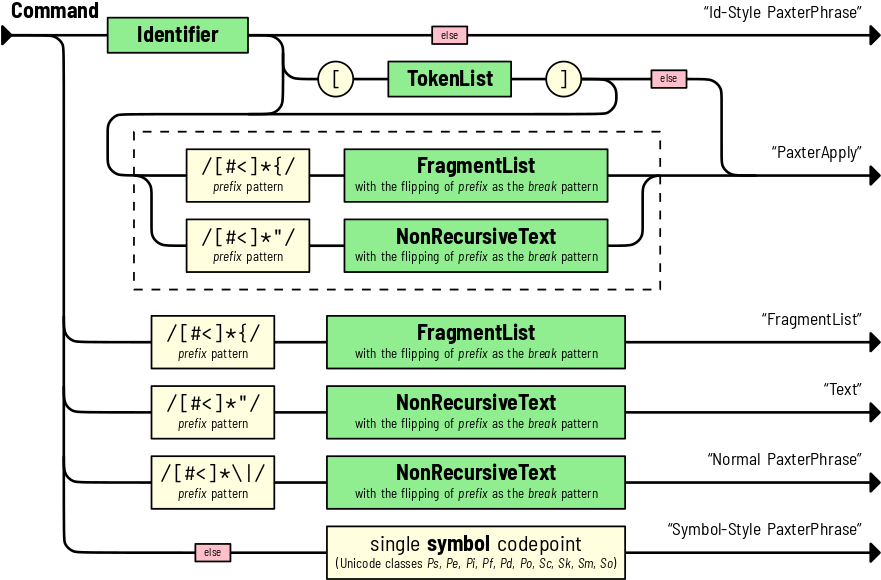
FragmentListnode type whose children is a list ofTextor command tokens.Command: Parses right after the @-symbol for one of 6 possibilities.
Note
The red
elsebox in this diagram indicates that such path can be followed only if the next token does not match any other possible paths. Walking through the boxes in itself consumes nothing.Note
The prefix pattern matched before the fragment list or the non-recursive text will be used to determine the break pattern indicating when to stop parsing for the fragment list or the non-recursive text itself, respectively. The break pattern is generally the mirror image of the matched prefix pattern, and can be computed by flipping the entire string as well as flipping each individual character to its mirror counterpart.
Possible results are:
A
PaxterApplywhich consists of an identifier, followed by at least one option section or one main argument section. The option section is a list of tokens enclosed by a pair of square brackets (node is represented withTokenList). On the other hand, the main argument section (surrounded by the dashed box in diagram below) is either a fragment list (represented withFragmentList) or a non-recursive raw text (represented withText).However, if the token immediately succeeding the identifier neither does match the option section path nor does match the main argument path, the the parsing results in the identifier-style
PaxterPhrasewhose inner phrase content derives from the identifier string.If the command begins with the brace prefix pattern, then the parsing yields the
FragmentListnode as a result.If the command begins with the quoted prefix pattern, then the parsing yields a regular
Textnode as a resultIf the command begins with the bar prefix pattern, then the parsing outputs the normal
PaxterPhrasenode.Finally, if the first token found does not match any of the above scenarios, then a single symbol codepoint is consumed and such character becomes the inner phrase content of symbol-style
PaxterPhrase.
TokenList: A sequence of zero or more tokens Each token either a command, an identifier, an operator, a number following JSON specification, or a nested token list enclosed by a pair of parentheses
(), a pair of square brackets[], or a pair of pure braces{}. The result is aTokenListnode type.
Note
The option section (or the token list) is the only place where whitespaces are ignored (when they appear between tokens).
Identifier: Generally follows Python rules for parsing identifier token (with some exceptions). The result is an
Identifiernode type.
Operator: Greedily consumes as many operator character as possible (with two notable exceptions: a comma and a semicolon, which has to appear on their own). A whitespace may be needed to separate two consecutive, multi-character operator tokens. The result is an
Operatornode type.
NonRecursiveText: Parses the text content until encountering the break pattern. As opposed to fragment list, no @-symbol will be recognized as the indicator of the beginning of a command.
Text extracted through this process will be used as the inner content of either
TextorFragmentListwhile a command is being parsed.