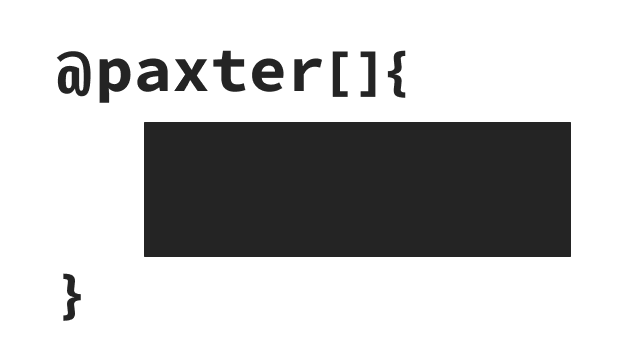
Syntax Reference¶
Below are syntax descriptions of Paxter language.
Document Rule¶
The starting rule of Paxter language grammar
which is a special case of FragmentSeq Rule.
The result of parsing this rule is always
a FragmentSeq node
whose children includes non-empty strings
(as Text nodes),
interleaving with the result produced by Command Rule.

Command Rule¶
Rule for parsing the textual content after
encountering the @-switch symbol character.
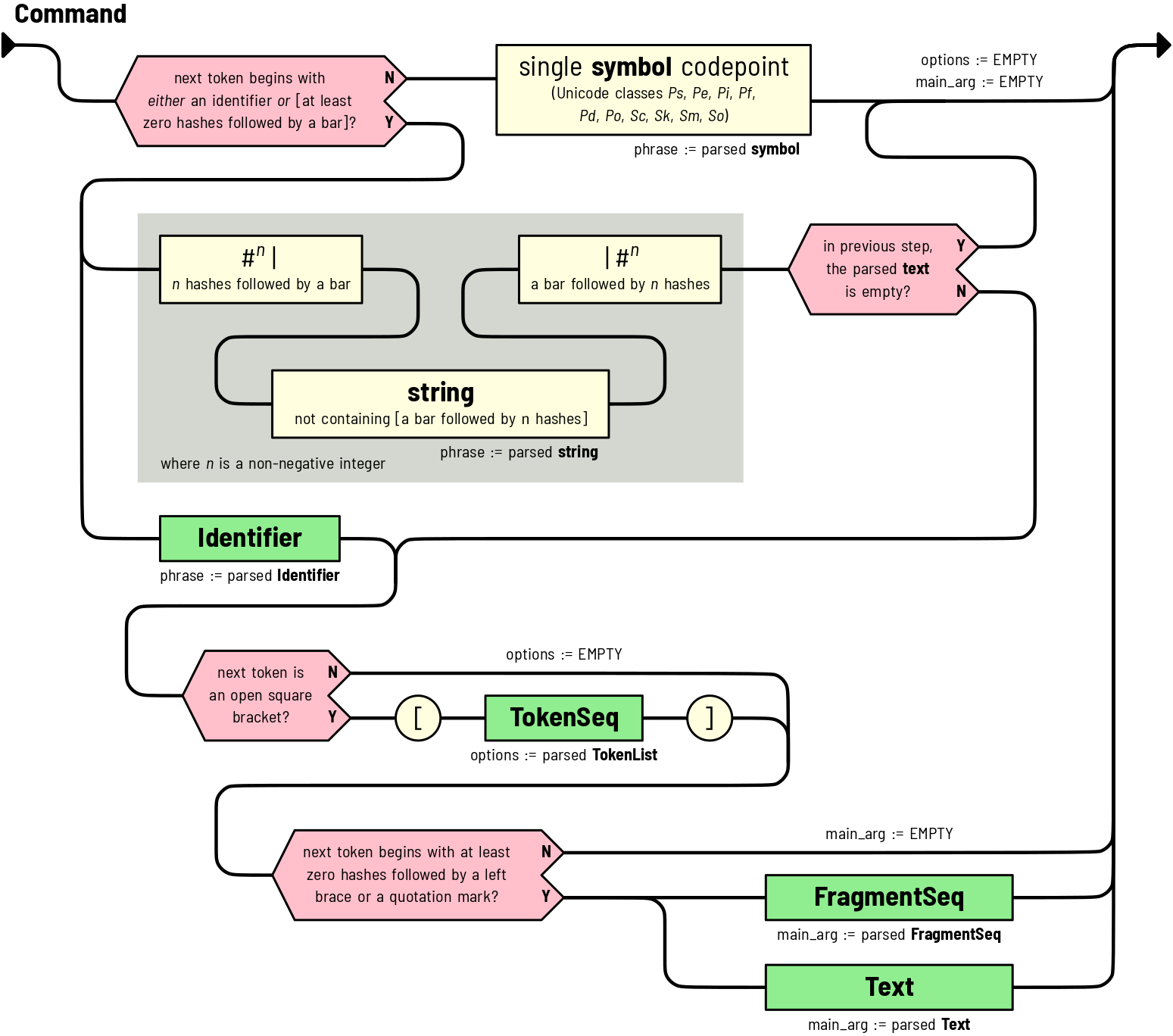
What are the red shapes?
Red shapes appeared in the above diagram indicates a branching path of parsing depending on conditions specified with the shapes.
There are a few possible scenarios.
The first token is an identifier. The parsed identifier becomes the phrase part of the
Command. Then the parser would attempt to parse the options section and the main argument section if they exist.The first token is \(n\) hash characters followed by a bar character. Then the parser will attempt to parse for the phrase part non-greedily until a bar character followed by \(n\) hash characters are found. If the parsing result of the phrase is not empty, then the parser would continue on trying to parse for the options section and the main argument section.
However, if the phrase is empty, then the options section as well as the main argument section are assumed to be empty.
The first token is a single symbol character. This would result in such symbol becoming the sole content of the phrase section, while other sections (i.e. options and main argument) are empty.
FragmentSeq Rule¶
This rule always begins with \(n\) hash characters followed by a left brace
and ends with a right brace followed by \(n\) hash characters,
for some non-negative integer \(n\).
Between this pair of curly braces is an interleaving of strings
(as Text)
and Command,
all of which are children of FragmentSeq instance.
One important point to note is that each string is parsed non-greedily; each resulting string would never contain a right brace followed by \(n\) or more hash characters.

Text Rule¶
This rule is similar to FragmentSeq Rule except for two main reasons.
The first reason is that nested Command
will not be parsed (i.e. "@" is not a special character in this scope).
Another reason is that, instead of having a matching pair of curly braces
indicate the beginning and the ending of the rule,
quotation marks are used instead.

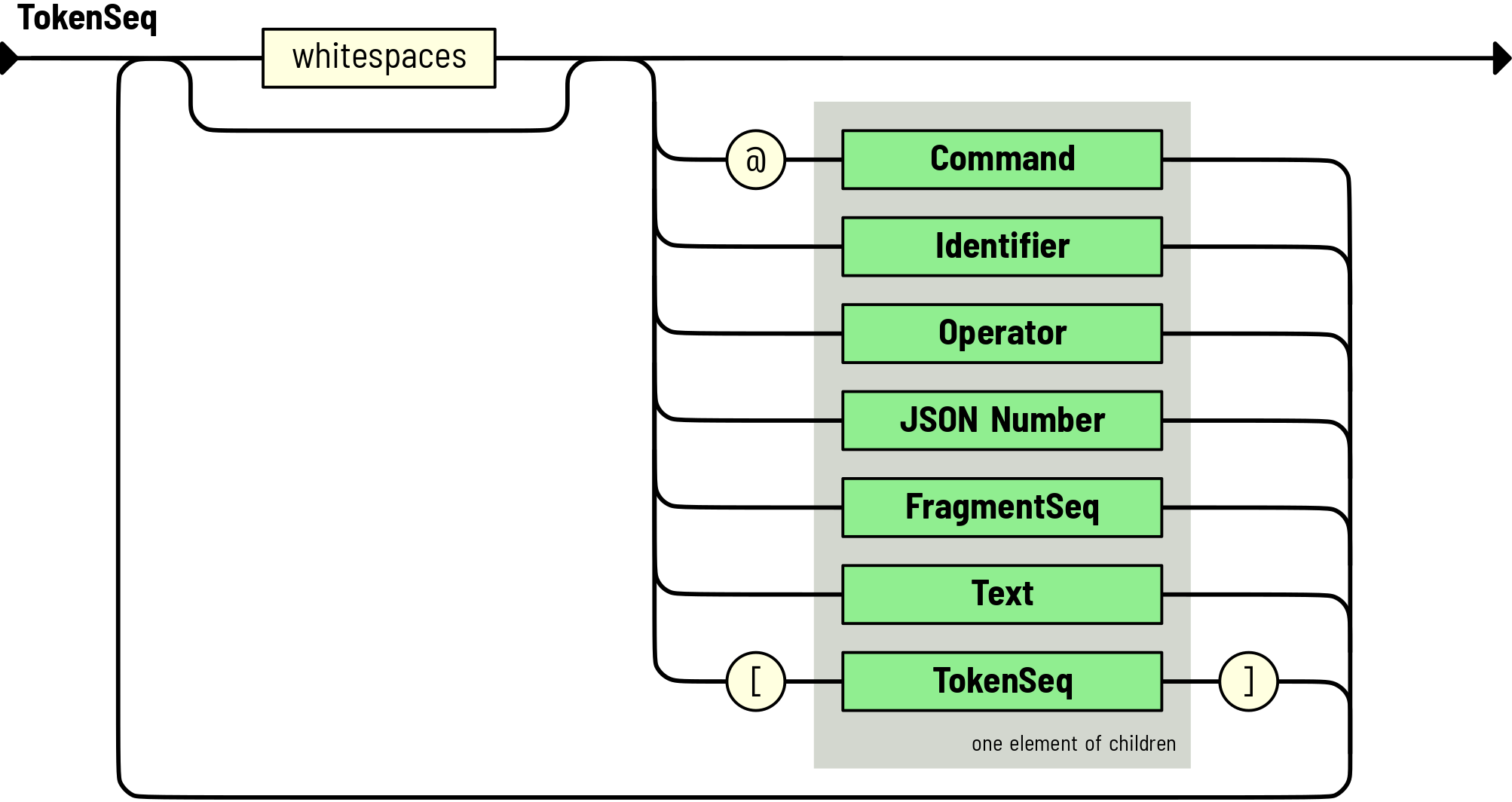
TokenSeq Rule¶
Following this parsing rule results in a sequence of zero or more tokens,
possibly separated by whitespaces.
Each token may be a Command,
an Identifier,
an Operator,
a Number,
a FragmentSeq,
a Text,
or a nested TokenSeq.
This resulting sequence of tokens are children of
TokenSeq node type.
Good To Know
The option section (or the token list) is the only place where whitespaces are ignored when they appear between tokens.
Identifier Rule¶
This rule generally follows python rules for greedily parsing
an identifier token (with some extreme exceptions).
The result is an Identifier node type.
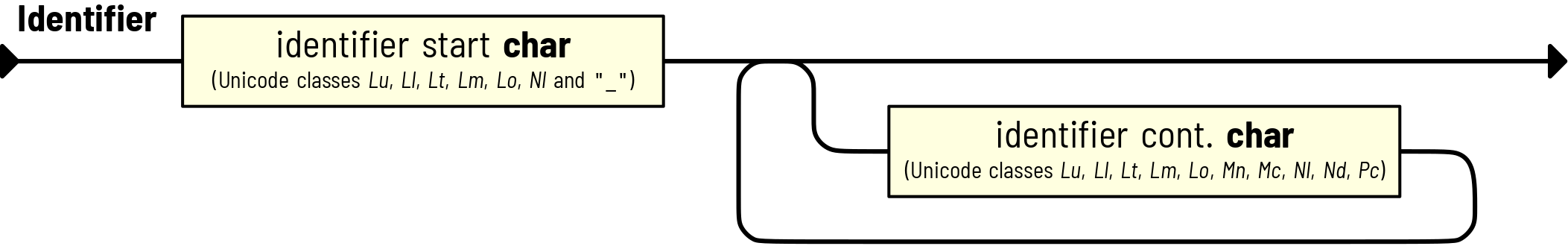
Operator Rule¶
Greedily consumes as many operator characters as possible
(with two notable exceptions: a common and a semicolon,
each of which has to appear on its own).
Whitespace characters may be needed to separate two consecutive,
multi-character operator tokens.
The result is an Operator node type.
